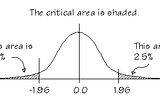
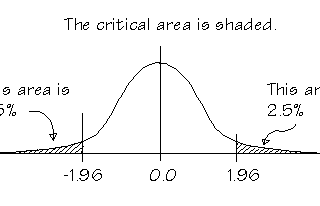
Abhishek BaraiinAnalytics VidhyaHypothesis Testing | All a beginner needs to knowHypothesis and Hypothesis testing:Nov 29, 2020Nov 29, 2020
Abhishek BaraiinAnalytics VidhyaProbability Distributions in Data Science and Machine Learning | Part 2Note: This blog is a continuum of “Probability Distributions in Data Science and Machine Learning | Part 1”. In case you haven’t read it…Nov 24, 2020Nov 24, 2020
Abhishek BaraiinAnalytics VidhyaProbability Distributions in Data Science and Machine Learning | Part 1For a data scientist aspirant, Statistics is a must-learn thing. It can process complex and challenging problems in the real world so that…Nov 24, 2020Nov 24, 2020
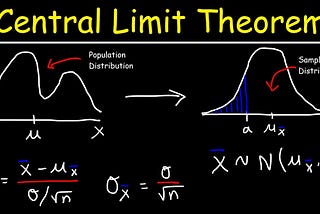
Abhishek BaraiinAnalytics VidhyaCentral Limit Theorem and Machine Learning | Part-2This blog is a continuation of “Central Limit Theorem and Machine Learning”. Please visit the part-1 for prior knowledge about the topic…Nov 22, 20201Nov 22, 20201
Abhishek BaraiinAnalytics VidhyaCentral Limit Theorem and Machine Learning | Part-1Note: Here I will try to cover the idea of the Central Limit Theorem, and it’s significance in statistical analysis, and how it is useful…Nov 22, 2020Nov 22, 2020
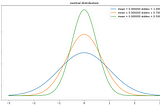
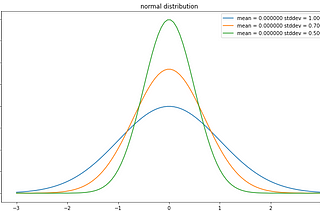
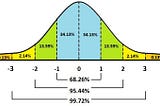
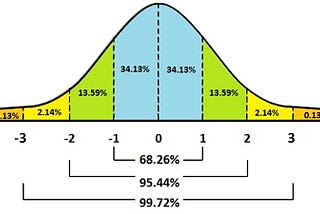
Abhishek BaraiinAnalytics VidhyaNormal Distribution and Machine LearningNormal Distribution is an important concept in statistics and the backbone of Machine Learning. It is essential for a Data Scientist to…Nov 19, 20203Nov 19, 20203
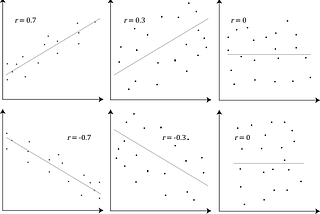
Abhishek BaraiinAnalytics VidhyaCorrelation and Machine LearningIn a statistical study which may be scientific, economic, social studies, or machine learning, sometimes we come across a large number of…Nov 18, 2020Nov 18, 2020
Abhishek BaraiA Self Case Study on Quora Insincere Question ClassificationNote: Here, I will try to explain how I approach the problem statement starting from exploratory data analysis to model building using…Nov 8, 20201Nov 8, 20201